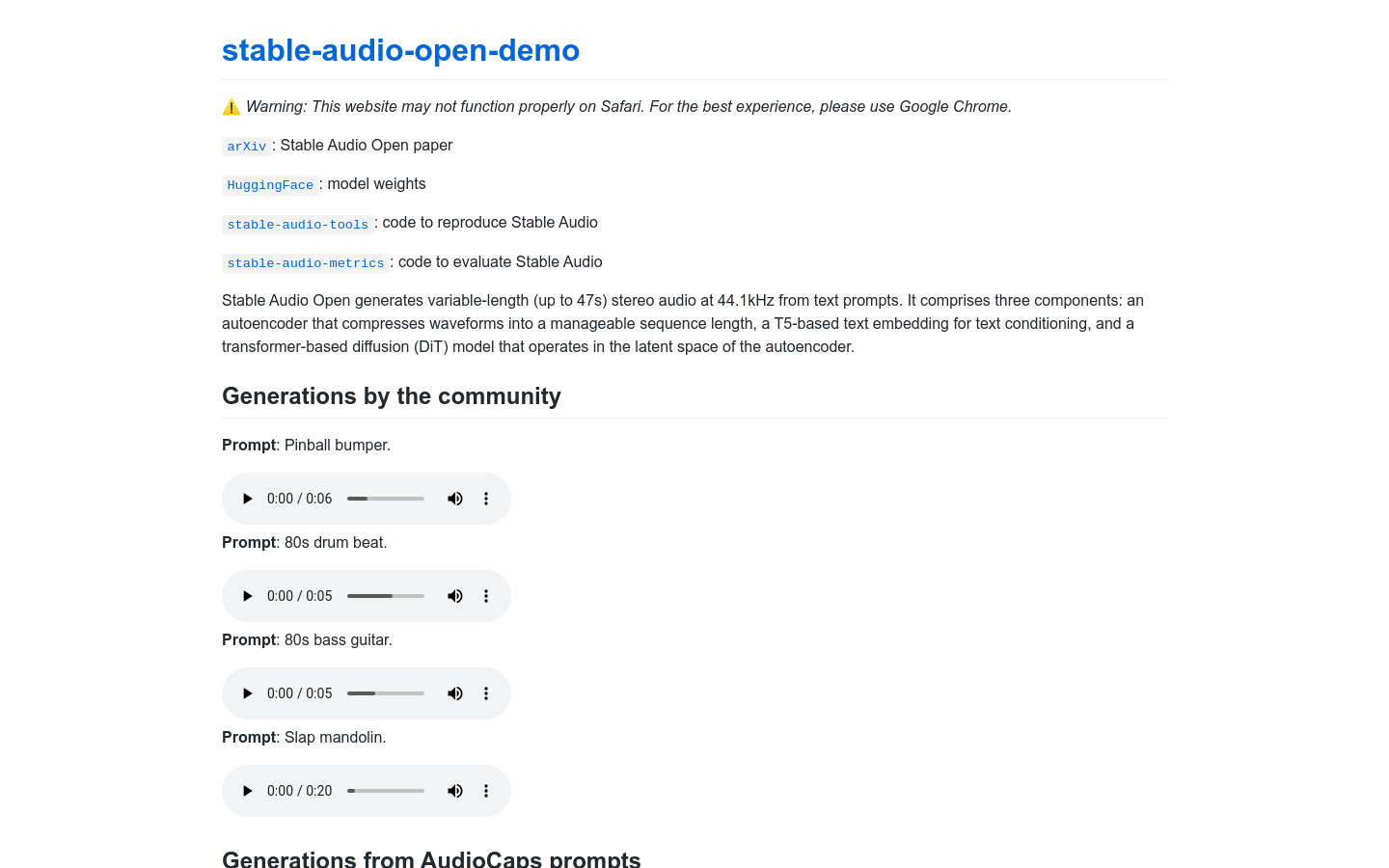
Stable Audio Open demo
从文本提示生成立体声音频
- 生成长达47秒的立体声音频
- 支持44.1kHz的音频采样率
- 使用自编码器压缩波形
- 基于T5的文本嵌入技术
- 基于变换的扩散模型(DiT)
- 社区生成的音频示例展示
- 音频记忆分析,确保生成内容的原创性
产品详情
Stable Audio Open 是一个能够从文本提示生成长达47秒的立体声音频的技术。它包含三个主要组件:一个将波形压缩到可管理序列长度的自编码器、一个基于T5的文本嵌入用于文本条件、以及一个在自编码器的潜在空间中操作的基于变换的扩散(DiT)模型。该技术在生成音频方面表现出色,能够根据文本提示生成各种类型的音频,如打击乐、电子音乐、自然声音等。