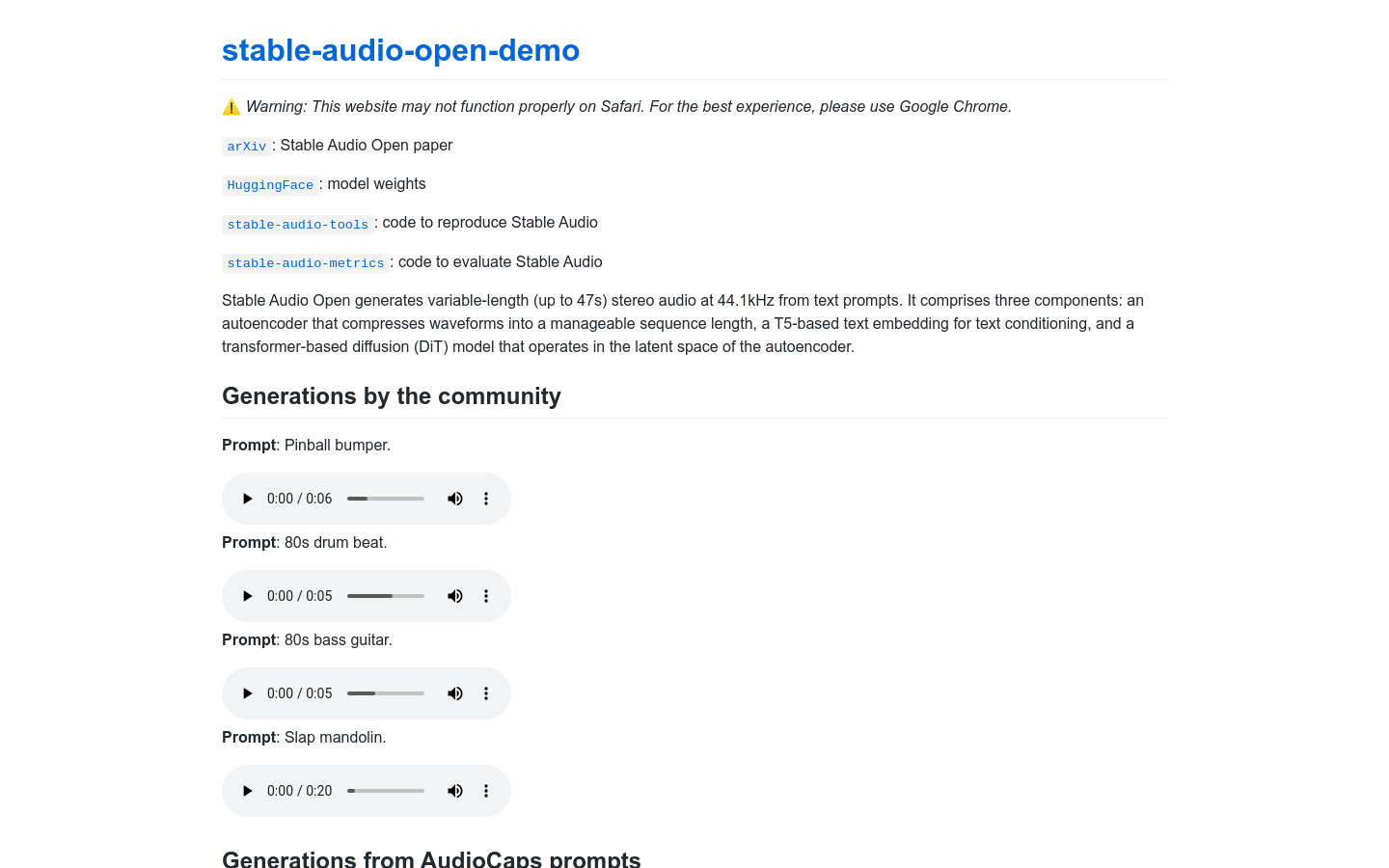
Stable Audio Open demo
Generate stereo audio from text prompts
- Generate stereo audio for up to 47 seconds
- Supports an audio sampling rate of 44.1kHz
- Compressing waveforms using autoencoders
- Text embedding technology based on T5
- Transformation based diffusion model (DiT)
- Community generated audio example display
- Audio memory analysis to ensure the originality of generated content
Product Details
Stable Audio Open is a technology that can generate up to 47 seconds of stereo audio from text prompts. It consists of three main components: an autoencoder that compresses waveforms to manageable sequence lengths, a T5 based text embedding for text conditions, and a transform based diffusion (DiT) model that operates within the latent space of the autoencoder. This technology performs well in generating audio and can generate various types of audio based on text prompts, such as percussion, electronic music, natural sounds, etc.