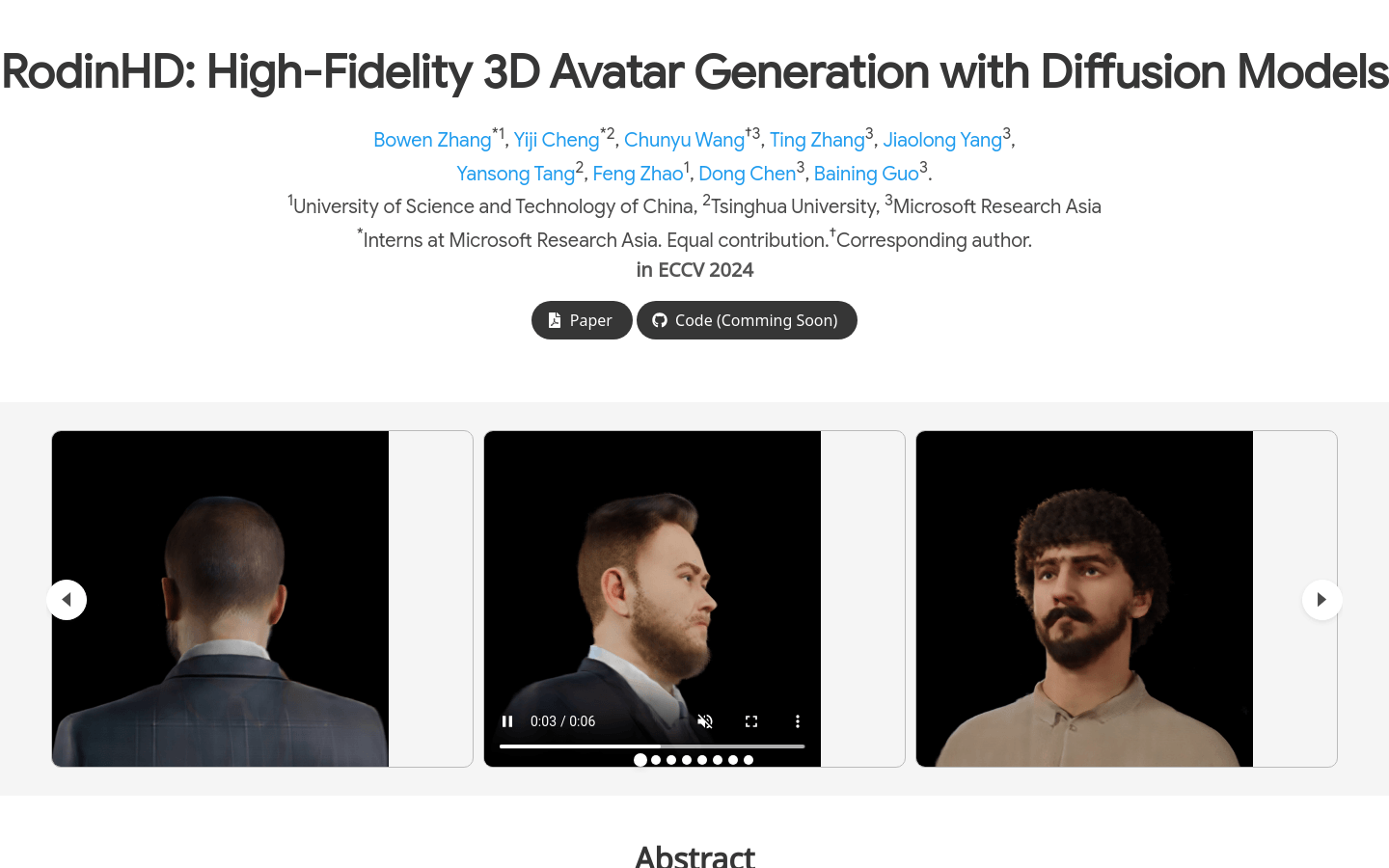
RodinHD
High fidelity 3D avatar generation model
- Generate high fidelity 3D avatars from a single portrait image
- Addressing the shortcomings of existing methods in capturing details
- Using innovative data scheduling strategies and weight integration regularization terms
- Optimizing portrait image guidance effect through multi-scale feature representation
- The generated 3D avatar has rich details and strong generalization ability
- Support conditional avatar generation and unconditional avatar generation
- Optimized noise plan to improve model training effectiveness
Product Details
RodinHD is a high fidelity 3D avatar generation technology based on diffusion models, developed by researchers such as Bowen Zhang and Yiji Cheng, aiming to generate detailed 3D avatars from a single portrait image. This technology addresses the shortcomings of existing methods in capturing complex details such as hairstyles, and improves the decoder's ability to render sharp details through novel data scheduling strategies and weight integration regularization terms. In addition, through multi-scale feature representation and cross attention mechanism, the guidance effect of portrait images has been optimized, and the generated 3D avatars are significantly better in details than previous methods, and can generalize to field portrait input.