ViTMatte
Improving image cutout based on pre trained pure visual transformer
- Combining hybrid attention mechanism with convolutional neck to optimize performance and balance computation
- Detail capture module, supplementing detail information through simple and lightweight convolution
- Multiple pre training strategies to enhance model generalization ability
- Concise architecture design, easy to understand and apply
- Flexible reasoning strategies to adapt to different scenario requirements
- Achieve state-of-the-art performance in commonly used image cutout benchmark tests
Product Details
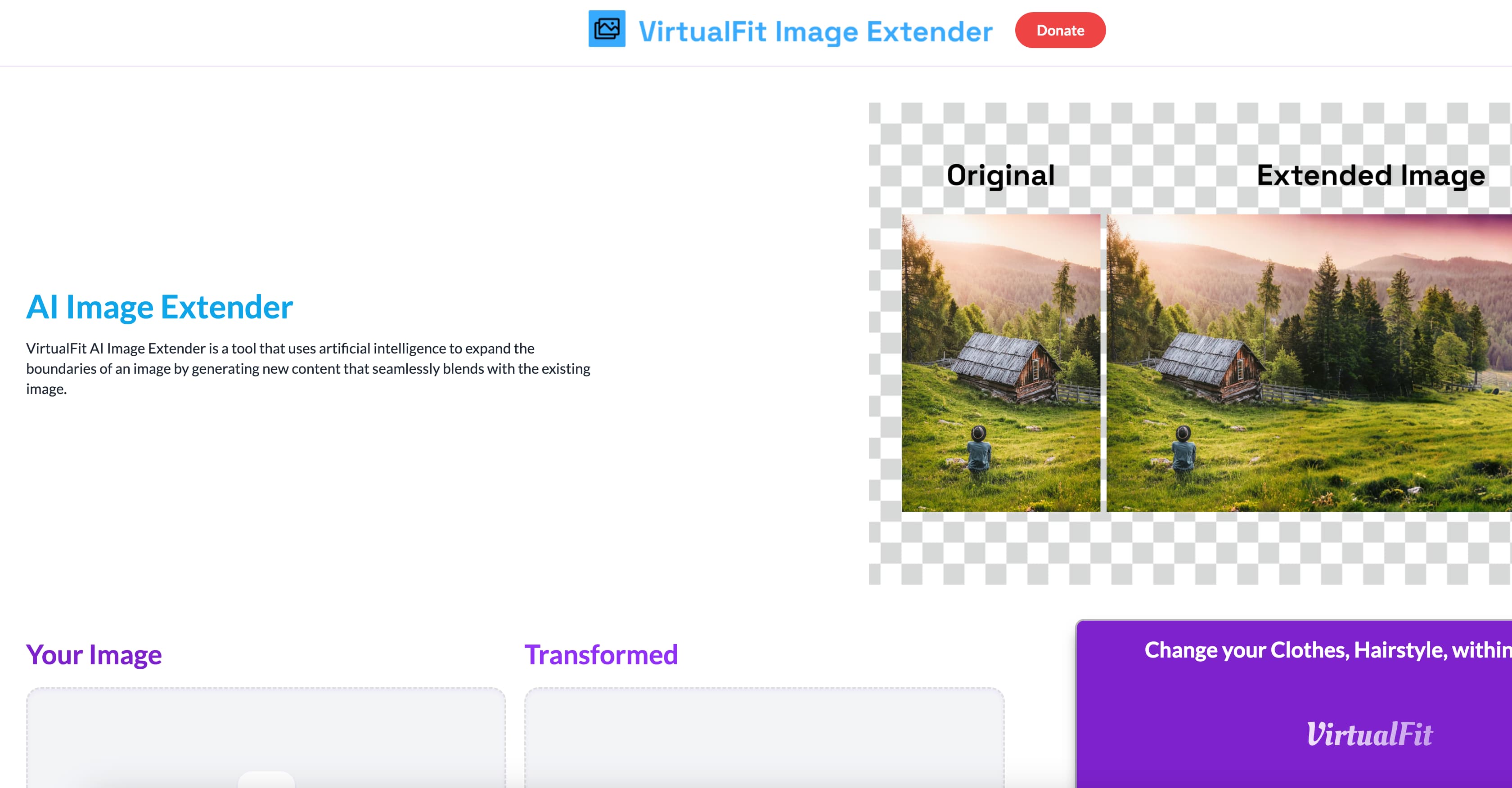
ViTMatter is an image cutout system based on pre trained Plain Vision Transformers (ViTs). It utilizes a hybrid attention mechanism and convolutional neck to optimize the balance between performance and computation, and introduces a detail capture module to supplement the detail information required for image segmentation. ViTMatter is the first work to unleash the potential of ViT in the field of image cutout through concise adaptation, inheriting the advantages of ViT in pre training strategies, concise architecture design, and flexible inference strategies. In the two most commonly used image cutout benchmark tests, Composition-1k and Distinctions-646, ViTMatter achieved state-of-the-art performance and surpassed previous work with significant advantages.