SenseVoiceSmall
Multi language high-precision speech recognition model
- Automatic Speech Recognition (ASR): capable of recognizing and converting speech into text.
- Spoken Language Recognition (LID): Identify the language in speech.
- Speech Emotion Recognition (SER): Identifying emotions in speech.
- Audio Event Detection (AED): detects specific events in audio, such as background music, applause, laughter, etc.
- Efficient reasoning: The SenseVoice Small model has extremely low inference latency and fast processing speed.
- Convenient fine-tuning: Provides fine-tuning scripts and strategies that are easy to adjust according to business scenarios.
- Multi language support: Supports speech recognition and emotion recognition in multiple languages.
Product Details
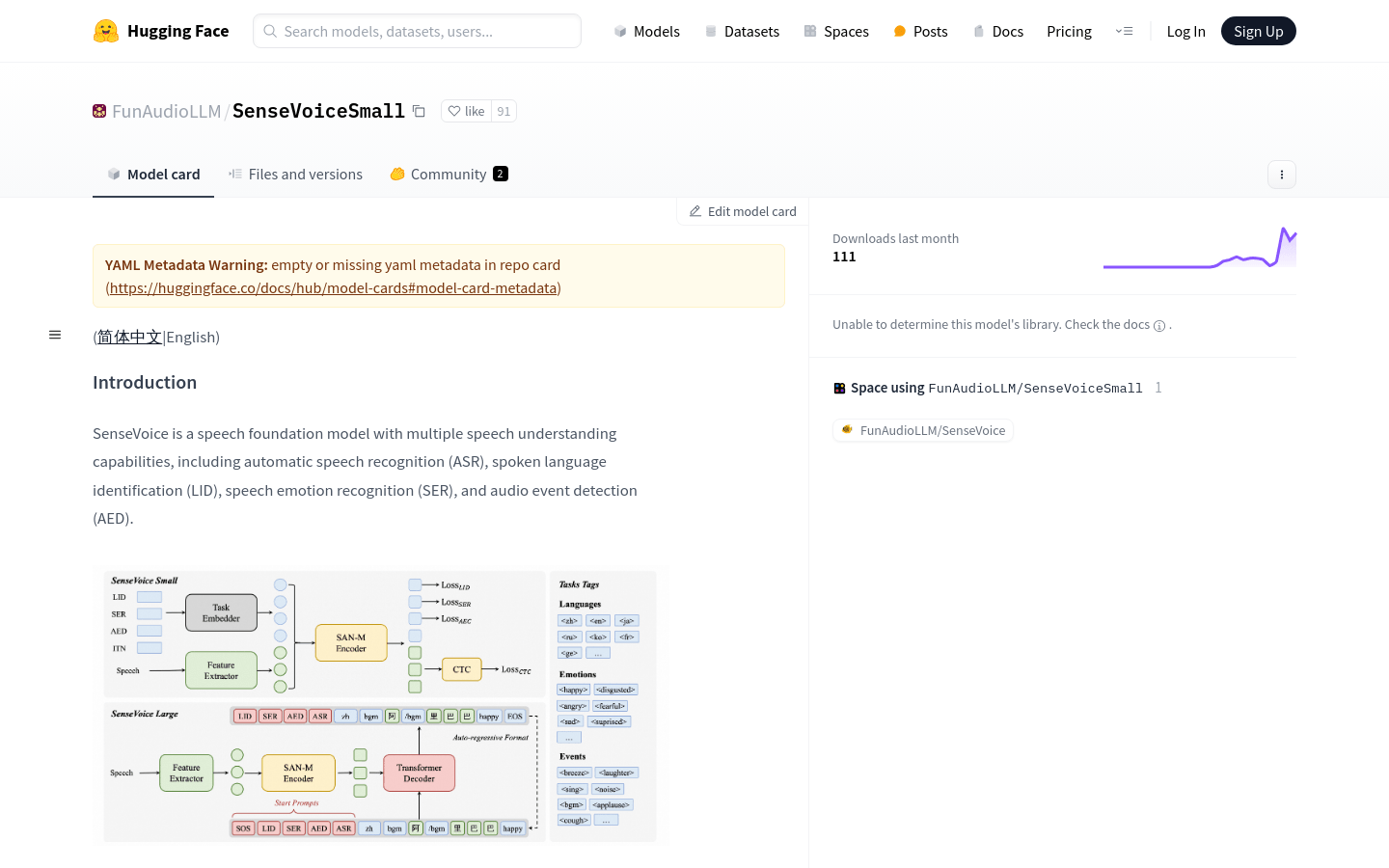
SenseVoiceSmall is a speech based model with multiple speech understanding capabilities, including automatic speech recognition (ASR), spoken language recognition (LID), speech emotion recognition (SER), and audio event detection (AED). The model has undergone over 400000 hours of data training, supports over 50 languages, and outperforms the Whisper model in recognition performance. Its small model SenseVoice Small adopts a non autoregressive end-to-end framework, with extremely low inference latency. It only takes 70 milliseconds to process 10 second audio, which is 15 times faster than Whisper Large. In addition, SenseVoice also provides convenient fine-tuning scripts and strategies, supports service deployment pipelines with multiple concurrent requests, and client languages include Python, C++, HTML, Java, and C #.