VideoVAEPlus
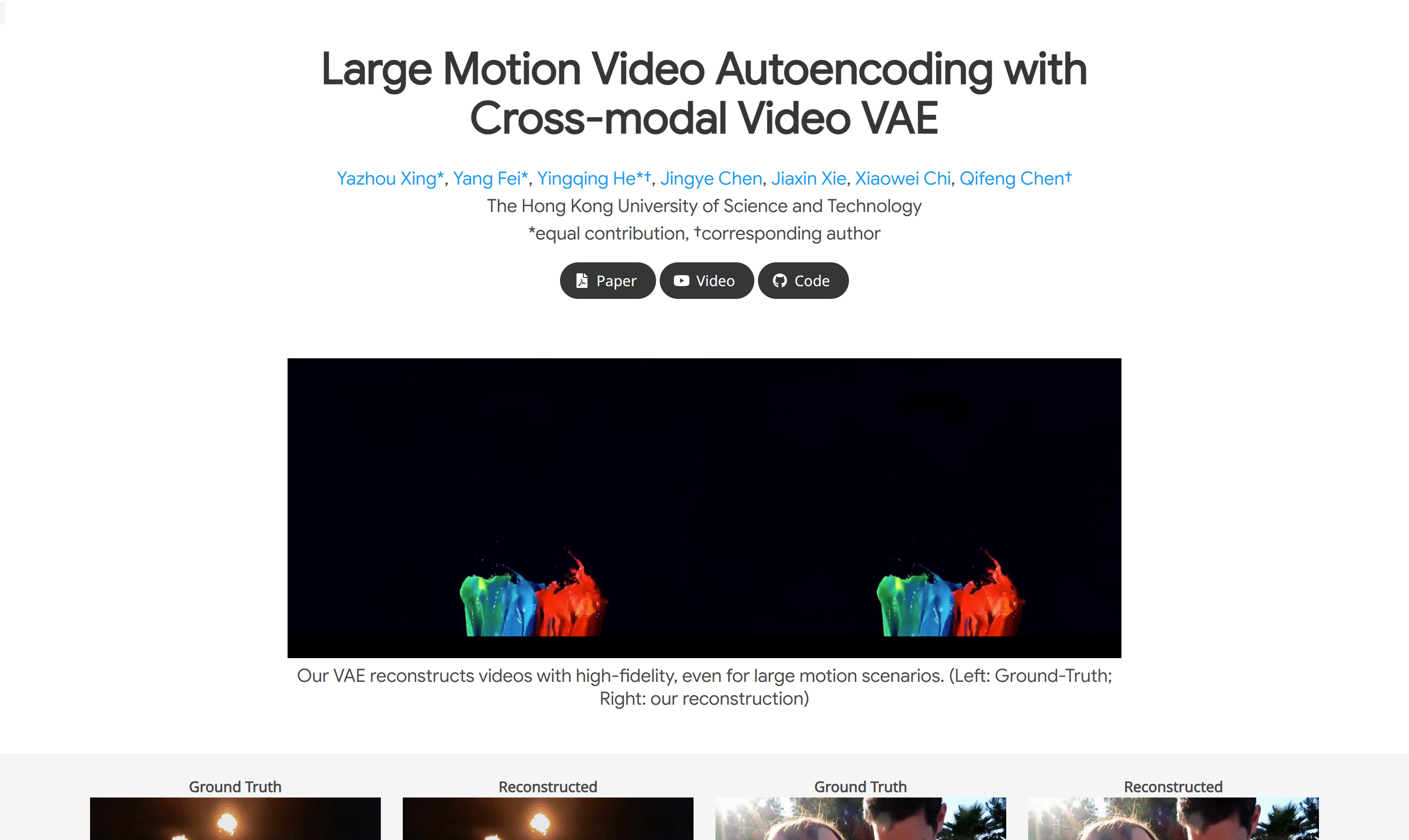
High fidelity video encoding, suitable for video autoencoders in large motion scenes.
0
- -High fidelity video encoding: can maintain video quality even in large motion scenes.
- -Time aware spatial compression: better encoding and decoding of spatial information, reducing motion blur and detail distortion.
- -Lightweight motion compression model: further implement time compression to improve compression efficiency.
- -Text guidance: Utilize text information from text to video datasets to improve reconstruction quality.
- -Joint training: Train on images and videos to enhance the generality and reconstruction quality of the model.
- -Detail preservation and temporal stability: Special emphasis is placed on maintaining detail and temporal stability in video reconstruction.
- -Cross modal video VAE: Combining text and video information to enhance the performance of video encoding.
Product Details
This is a video variational autoencoder (VAE) designed to reduce video redundancy and promote efficient video generation. The model observed that directly extending image VAE to 3D VAE would introduce motion blur and detail distortion, thus proposing temporal aware spatial compression to better encode and decode spatial information. In addition, the model also integrates a lightweight motion compression model to achieve further time compression. By utilizing the inherent textual information in the text to video dataset and incorporating text guidance into the model, the reconstruction quality has been significantly improved, especially in terms of detail preservation and temporal stability. The model also improves its generality by jointly training on images and videos, which not only enhances the reconstruction quality but also enables the model to perform self encoding of images and videos. Extensive evaluations have shown that the performance of this method is superior to recent strong baselines.