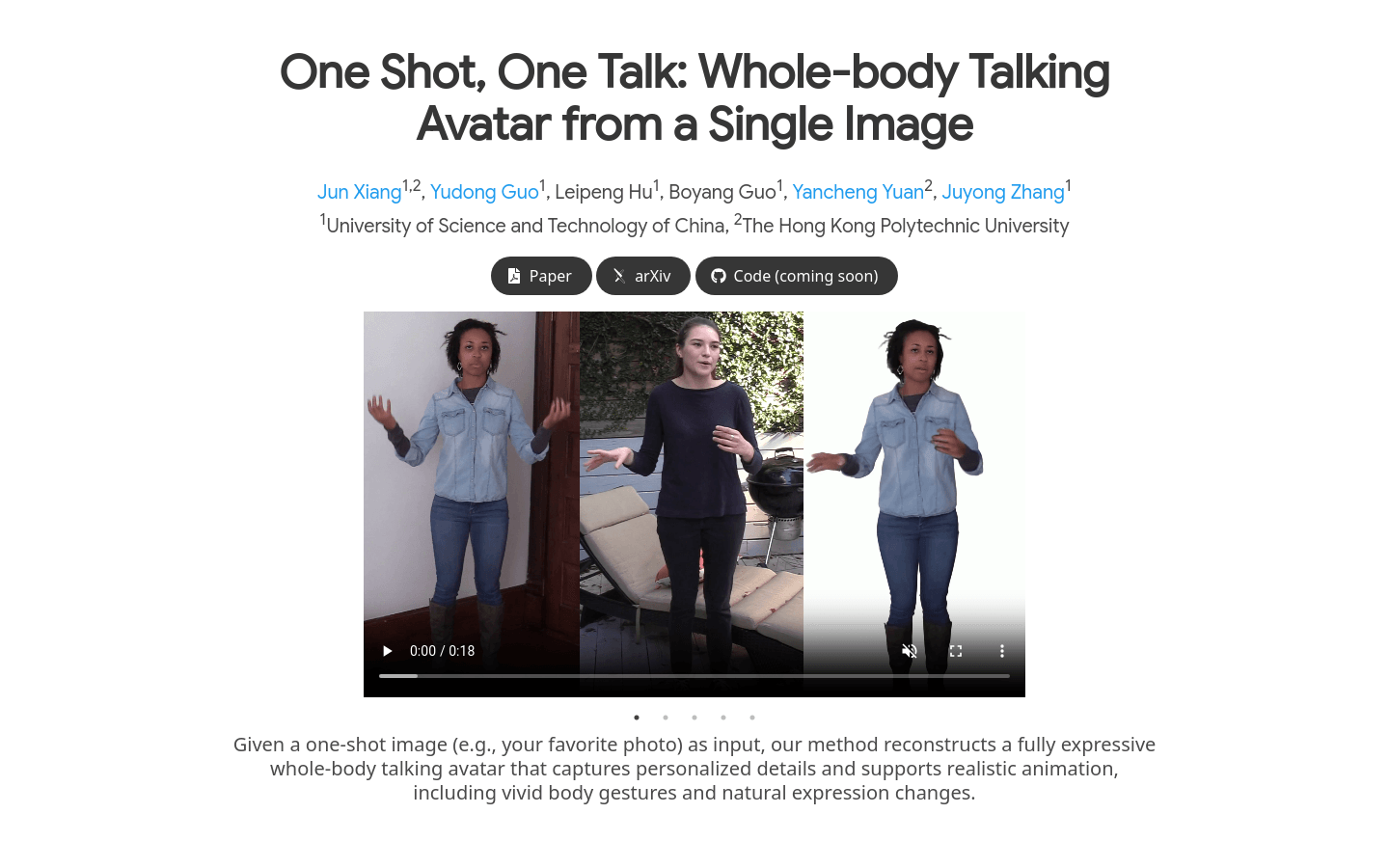
One Shot, One Talk
Create a full body dynamic speaking avatar from a single image
0
- -Single image input: Users only need to provide one image to generate a full body dynamic speaking avatar.
- -Realistic animation: The generated avatar can perform realistic animation expressions, including body movements and facial expressions.
- -Personalized details: Avatar can capture and reproduce users' personalized features.
- -Dynamic modeling: Using complex dynamic modeling techniques to achieve natural actions of avatars.
- -Pseudo label generation: Using pre trained generation models, generate imperfect video frames as pseudo labels.
- -3DGS mesh hybrid avatar representation: Combining 3DGS mesh and mesh representation to enhance the realism and expressiveness of avatars.
- -Key regularization techniques: reduce inconsistencies caused by imperfect labels and improve avatar quality.
- -Cross identity action replay: Using the same driving posture, avatars of different identities can be driven in the same way.
Product Details
One Shot, One Talk is a deep learning based image generation technology that can reconstruct full body dynamic speaking avatars with personalized details from a single image, and supports realistic animation effects, including vivid body movements and natural facial expressions. The importance of this technology lies in its significant reduction of the threshold for creating realistic and movable virtual images, allowing users to generate highly personalized and expressive virtual images with just one image. The product background information shows that this technology was developed by a research team from the University of Science and Technology of China and the Hong Kong Polytechnic University. It combines the latest image to video diffusion model and 3DGS mesh hybrid avatar representation, and reduces inconsistencies caused by imperfect labels through key regularization techniques.