Sketch2Sound
A model for generating controllable audio through time varying signals and sound imitation
0
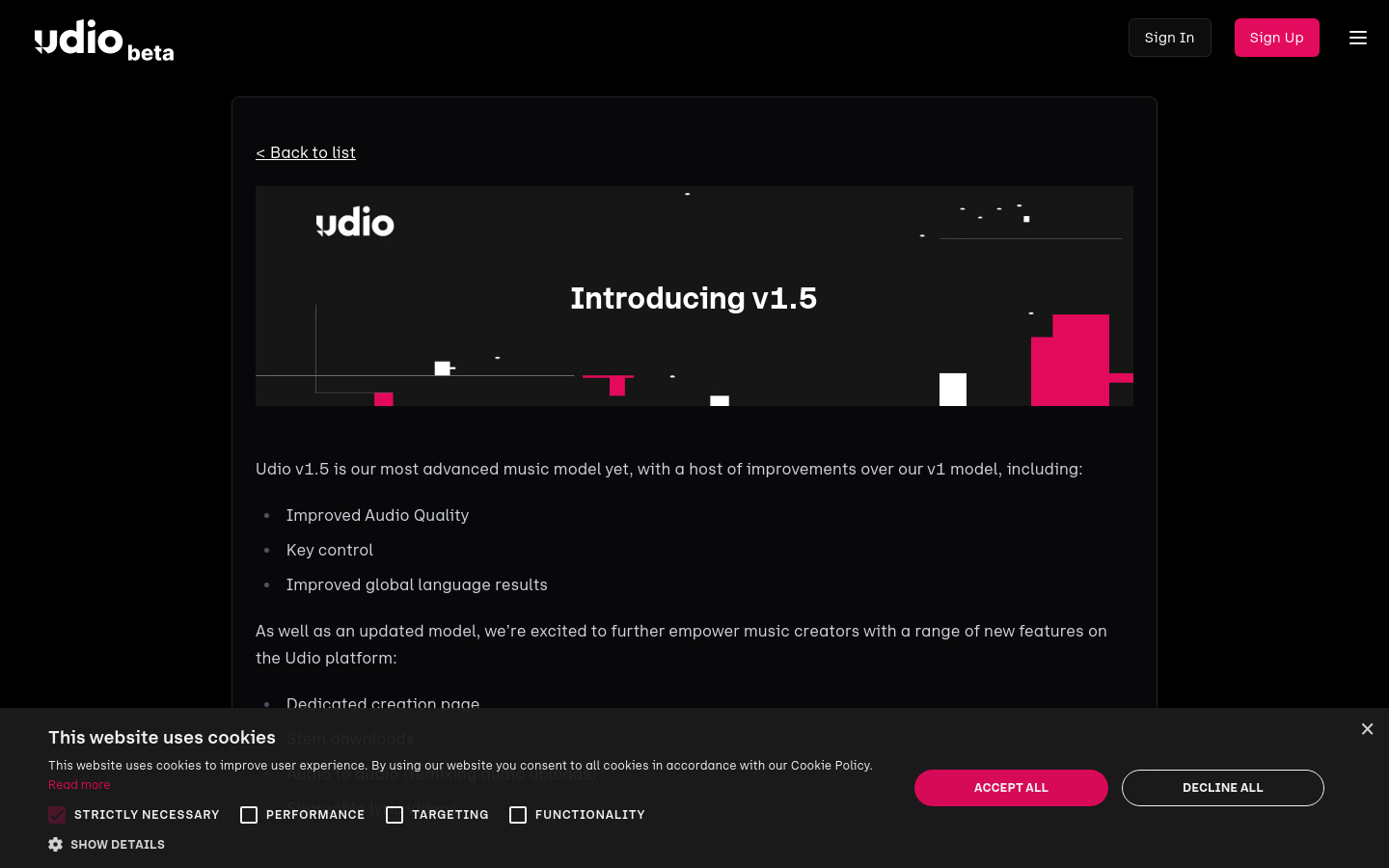
- -Synthesize any sound from sound imitation: Sketch2Sound can synthesize any sound based on sound imitation or reference sound shape.
- -Explainable Time Varying Control Signal: The model uses loudness, brightness, and pitch as control signals to generate audio.
- -Text prompt support: Sketch2Sound can generate semantic sound based on text prompts.
- -Lightweight implementation: Compared to other methods, Sketch2Sound requires fewer fine-tuning steps and linear layers.
- -Flexible control signal processing: Sketch2Sound can use control signals with different time specificities for prompting by applying random median filtering to the control signals during training.
- -Maintain audio quality: Compared to a baseline that only uses text, Sketch2Sound maintains audio quality while following input control.
- -Sketch2Sound provides a new tool for sound artists that combines text prompts and sound imitation.
Product Details
Sketch2Sound is a model for generating audio that can create high-quality sound from a set of interpretable temporal control signals (loudness, brightness, pitch) and text prompts. This model can be implemented on any text to audio latent diffusion transformer (DiT) and only requires 40k fine-tuning steps and a separate linear layer for each control, making it more lightweight than existing methods such as ControlNet. The main advantages of Sketch2Sound include the ability to synthesize any sound from sound imitation, as well as following the general intent of input control while maintaining input text prompts and audio quality. This enables sound artists to create sound by combining the semantic flexibility of text prompts with the expressiveness and precision of sound gestures or sound imitation.